Cluster vendors: Dell, HP, Aspen Systems, Microway, RackSaver, Paralogic, etc
---------------------------------------------------
I. Computational Clusters
Parallel numerical simulations
Several distributed processes are involved in computing the same
numerical application.
High performance computational applications:
Computational Fluid dynamics
Automotive modeling
Materials research
Computational Physics
Computational Chemistry
Financial modeling
Shared Memory model:
Example: Cray YMP C/J 90, SGI Origin 200/2000, Sun E10000
Message Passing model
Example: Cray T3E, Unix (Linux) clusters
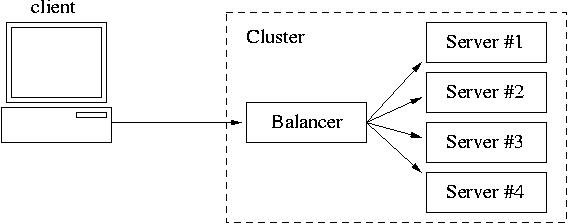
Computational cluster diagram
 |
What makes a bunch of computers on a network to become a
computational cluster:
A) Single system Image (SSI). For example, OpenMosix. SSI is smart system
software that spreads operating system functions across systems and involves
modifications of the Linux kernel.
OR/AND
B) Single System Environment (SSE) - a smart system software that runs in
user space as layered service. SSE includes, for example:
API libraries for programming, for example, PVM and MPI
Queue scheduling system (for example, LSF, Condor, PBS and Grid Engine )
Examples of computational software utilizing MPI:
FLUENT (Fluid Dynamics and Heat transfer)
GASP (Gas Dynamics)
AMBER (Molecular dynamics)
NAMD (MOlecular dynamics)
Message Passing Interface (MPI)
Simplified MPI funcion call structure (for C codes):
MPI_init()
MPI_Comm_size()
MPI_Comm_rank()
MPI_Bcast()
MPI_Send()
MPI_Recv()
MPI_Finalize()
MPI program example, mpi_message.c: the master process sends an array
to the slave processes;
the slave processes compute partial sums and send them to the master;
the master computes a cumulative total sum.
#include <stdio.h>
#include <math.h>
#include "mpi.h"
#define ASIZE 100
#define pi 3.141592653589793238462643
void main(int argc, char **argv)
{
int me, nprocs, namelen;
char processor_name[MPI_MAX_PROCESSOR_NAME];
int i;
double seed, init_val[ASIZE], val[ASIZE], sum, tsum;
MPI_Status status;
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &nprocs);
MPI_Comm_rank(MPI_COMM_WORLD, &me);
MPI_Get_processor_name(processor_name, &namelen);
if (me == 0 )
{ /* only the 1-st procesor in the group */
printf("Enter some kind of seed value:\n");
scanf("%f", &seed);
for (i=0; i < ASIZE; i++)
init_val[i] = (double)i * seed * pi;
}
/* Broadcast computed initial values to all processors */
if (MPI_Bcast(init_val, ASIZE, MPI_DOUBLE, 0, MPI_COMM_WORLD)
!= MPI_SUCCESS)
fprintf(stderr, "Oops! An error occured in MPI_Bcast()\n");
for (i = 0, sum =0.0; i < ASIZE; i++)
{
val[i] = init_val[i] * me;
sum += val[i];
}
printf("%d: My sum id %lf\n", me, sum);
printf("Processor name %s\n", processor_name);
/* Send sum back to the first process */
if (me)
{
/* All processes except the 0 */
MPI_Send(&sum, 1, MPI_DOUBLE, 0, 1, MPI_COMM_WORLD);
}
else
{
tsum=sum;
for (i= 1; i < nprocs; i++)
{
MPI_Recv(&sum, 1, MPI_DOUBLE, MPI_ANY_SOURCE, 1, MPI_COMM_WORLD, &stat
us);
tsum += sum;
}
printf("%d: Total sum is %lf\n", me, tsum);
}
MPI_Finalize();
}
|
To compile the code:
mpicc -O -o mpi_message.x mpi_message.c
To run the code on 3 nodes:
mpirun -np 3 mpi_message.x
Grid Engine Queue Scheduling System (simlified):
Master host (controls queues, jobs, schedules on the whole cluster)
Computational hosts (run jobs)
The communication daemon opens TCP port 536.
-------------------------------------------------------------
II. Linux Virtual Servers (LVS)
A request for service comes to the Virtual IP address of the Traffic Director;
the Director re-directs the request to the least busy available real server;
the real servers run identical services (daemons, scripts and files).
LVS implementations
1. Network Address Translation (NAT)
2. Direct Routing
3. IP Tunneling
---------------------------------------------------------------------
---------------------------------------------------------------------
---------------------------------------------------------------------
Projects
Project 1
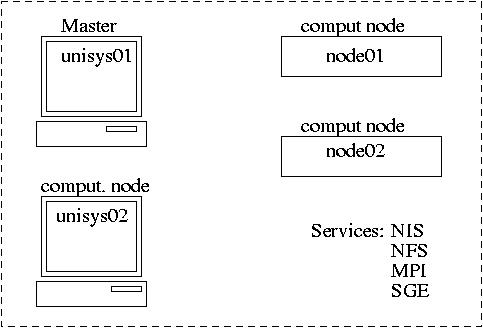
Computational cluster.
Project steps (3 weeks):
1. Compilation and installationof MPI; setup NIS and NFS.
2. Installation and configuration of SGE queue system.
3. Integration of MPI with SGE; Development of MPI computational code.
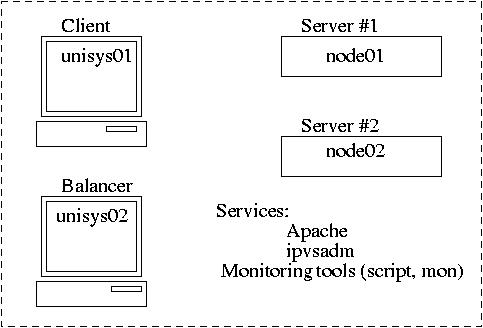
Project 2
Linux Virtual Server (LVS)
Project steps (3 weeks):
1. Installation of Apache on the server nodes; Configuration of VIP and NAT
on the balancer machine.
2. Installation of the Kernel for LVS and ipvsadm; configuration of LVS
for NAT and DR schemes; server monitoring script.
3. MON scheduler and alert management tool.
---------------------------------------------------------------------
Projects assignment due by next Wednesday
In the examples below, we use hosts unisys14, unisys15, node14 and node15.
Project 1: High Performance Computational Cluster: STEP 1
Install gcc compiler on one of your cluster machines;
download and install MPI on the cluster machines; compile
and run the sample code.
Installing MPI on computational nodes
If you run heterogeneous systems, like SPARCs and PCs, then install MPI
on a PC or one of the cluster nodes first: you need to download MPI and
compile it following their instructions. When you run ./configure, run
it with -prefix=/usr/local/mpich-1.2.5.
Then you can export the directory with MPI, /usr/local/mpich-1.2.5,
to the other computational nodes over NFS.
The directory has to be mounted as /usr/local/mpich-1.2.5 on the nodes.
Alternatively, you can copy /usr/local/mpich-1.2.5 to the other
hosts using rsync:
rsync -e ssh -avz /usr/local/mpich-1.2.5/ node01:/usr/local/mpich-1.2.5
Bind all of the computational nodes to the same NIS domain; use one of your
desk top machines as a NIS master. Export your /home from the
NIS master to the nodes; mount it on the nodes, accordingly.
Allow "rsh" connection between the computational nodes, for example, if you
are going to run MPI between unisys14, unisys15, node14 and node15,
include the following entries in /etc/hosts.equiv on these machines:
localhost
unisys14
unisys15
node14
node15
When you rsh between the machines, you should get into your home directory.
In directory /usr/local/mpich-1.2.5/util/machines/ (or /usr/local/mpich-1.2.5/share),
modify file machines.LINUX
creating a list of the machines participating into parallel simulations,
for example,
unisys14.rutgers.edu
unisys15.rutgers.edu
node14.rutgers.edu
node15.rutgers.edu
Include the MPI directory in your PATH variable on all the machines.
You can do it for all users, modifying file /etc/profile:
PATH=$PATH:/usr/local/mpich-1.2.5:/usr/local/mpich-1.2.5/bin:/usr/local/mpich-1.2.5/lib:/usr/local/mpich-1.2.5/include
Test the machines by running
tstmachines
You should be running it as a user in your home directory.
If it doesn't give you errors, then you are ready to compile and run your
first MPI program.
Project 2: Linux Virtual Server. Step 1
Install Apache server on the cluster machines,"apt-get install httpd".
Setup virtual IP address and NAT between two
cluster machines and one of your desktops;
I. Virtual IP interface and Masquerading
1. Setting up a vitual interface on unisys14:
Use the "ifconfig" command to set up virtual (fictitious) interface
on the same network card.
/sbin/ifconfig eth0:0 192.168.6.14 netmask 255.255.255.0 up
Check to see whether the interface "eth0:0" was created.
/sbin/ifconfig -a
2. Enable routing on unisys14 to act as a gateway and forward the packets
using the virtual interface you created.
echo 1 > /proc/sys/net/ipv4/ip_forward
Alternatively, you can modify file /etc/sysctl.conf as follows:
net.ipv4.ip_forward = 1
net.ipv4.conf.default.rp_filter = 1
kernel.sysrq = 0
Then enable the settings in the kernel:
/sbin/sysctl -p
3. Reconfigure unisys15 for the new IP address, 192.168.6.15, with
the same netmask, 255.255.255.0; the gateway will be unisys14 with
its new interface, 192.168.6.14. You need to modify your /etc/hosts,
/etc/sysconfig/network and /etc/sysconfig/network-scripts/ifcfg-eth0,
accordingly, then reboot the machine.
4. On unisys14, set iptables rule for masquerading to
masquerade the packets coming from 192.168.5.0/24 through unisys14.
Specify iptables rules:
/sbin/iptables -A POSTROUTING -t nat \
-s 192.168.5.0/24 -d ! 192.168.5.0/24 -j MASQUERADE
Make sure the rules are active:
/sbin/iptables -L -t nat
If you need to flush the iptables rules: /sbin/iptables -F -t nat
5. On node15, modify the routing table:
route add -net 192.168.6.0 netmask 255.255.255.0 gw 192.168.5.14
All connections initiated on node15 with 192.168.6.0/24 subnet would
be routed through unisys14 (192.168.5.14). You can check the new routing
with command netstat -nr
Now on node15, try pinging unisys15 on its new IP address again
ping 192.168.6.15
and also ssh (or telnet) to that machine:
ssh 192.168.6.15
6. Finally, re-analyze the connection on unisys15 to see how the packets
are forwarded. Refer to the following diagram for explanation:

|
You should be able to see with netstat -na
that unisys15 shows the connection with 192.168.6.14 other than
node14. In this case, unisys14 masquerades all packets coming from
192.168.5.0 subnet with its virtual IP address.
Read LVS-HOWTO and LVS mini HOWTO.